11月10日,“漢字守護計劃”公益行動發布一周年成果。官方指導“生僻字征集”小程序迄今有2500多萬人次參與,提交生僻字16800個。經工信部電子工業標準化研究院初篩,其中457個尚未獲得強制性國家標準GB 18030《信息技術 中文編碼字符集》編碼,以地名、人名、方言用字為主,具有較高的實用價值或文化價值。同日,“生僻字征集”小程序內上線“救字文檔”功能,繼續向公眾征集457個生僻字的相關考證資料,以協助專家組加快完成考證及編碼申請。
據不完全統計,全國有6000余萬人的姓名,以及大量地名、古籍、方言中包含生僻字,其中多數尚未實現數字化。去年11月,騰訊聯合工信部電子工業標準化研究院、光明日報全媒體、北京國家金融標準化研究院、漢儀字庫、OPPO、陜西歷史博物館等機構與企業,共同發起“漢字守護計劃”公益行動,發揮各自優勢并加大投入力度,加速貫通生僻字數字化全鏈路,旨在助力破解生僻字使用難題,重煥和傳承生僻字背后積淀的中華傳統文化。該計劃于今年4月20日世界中文日上線“生僻字征集”小程序,直接面向公眾征集無法輸入的生僻字。


生僻字數字化是一項復雜的系統工程,每個漢字應用于數字系統,都要經歷“發現、考證、編碼、擴容國標、字形設計、輸入顯示、推廣應用”等一系列環節。其中,漢字編碼環節周期長、復雜性高,要對漢字的實際使用范圍、形音義正確性、字形區別與認同、文獻用例等進行大量考證,涉及語言文字、文化、信息技術、標準化等多個領域,需投入大量人力查找文獻古籍、搜尋實際應用案例。按照常規流程和進度估算,完成這457個漢字的申請編碼資料至少需要兩年時間。
工信部電子工業標準化研究院中文信息研究室主任黃姍姍表示,“生僻字征集小程序以創新方式為‘收字’提供高效支撐,特別是此次篩選的457個未編碼漢字,更多來源于各地居民的日常生活,有著很深的群眾基礎和鮮活的社會生命力。電子工業標準化研究院正全力優先開展此批漢字的考證工作,加快推動編碼,擴容國標字庫。”
為進一步助力提升申請編碼資料的考證效率,“生僻字征集”小程序內全新上線 “救字文檔”功能,支持全國各地用戶低門檻參與,微信搜索“生僻字征集”小程序即可加入,填寫漢字的讀音、來源等信息。
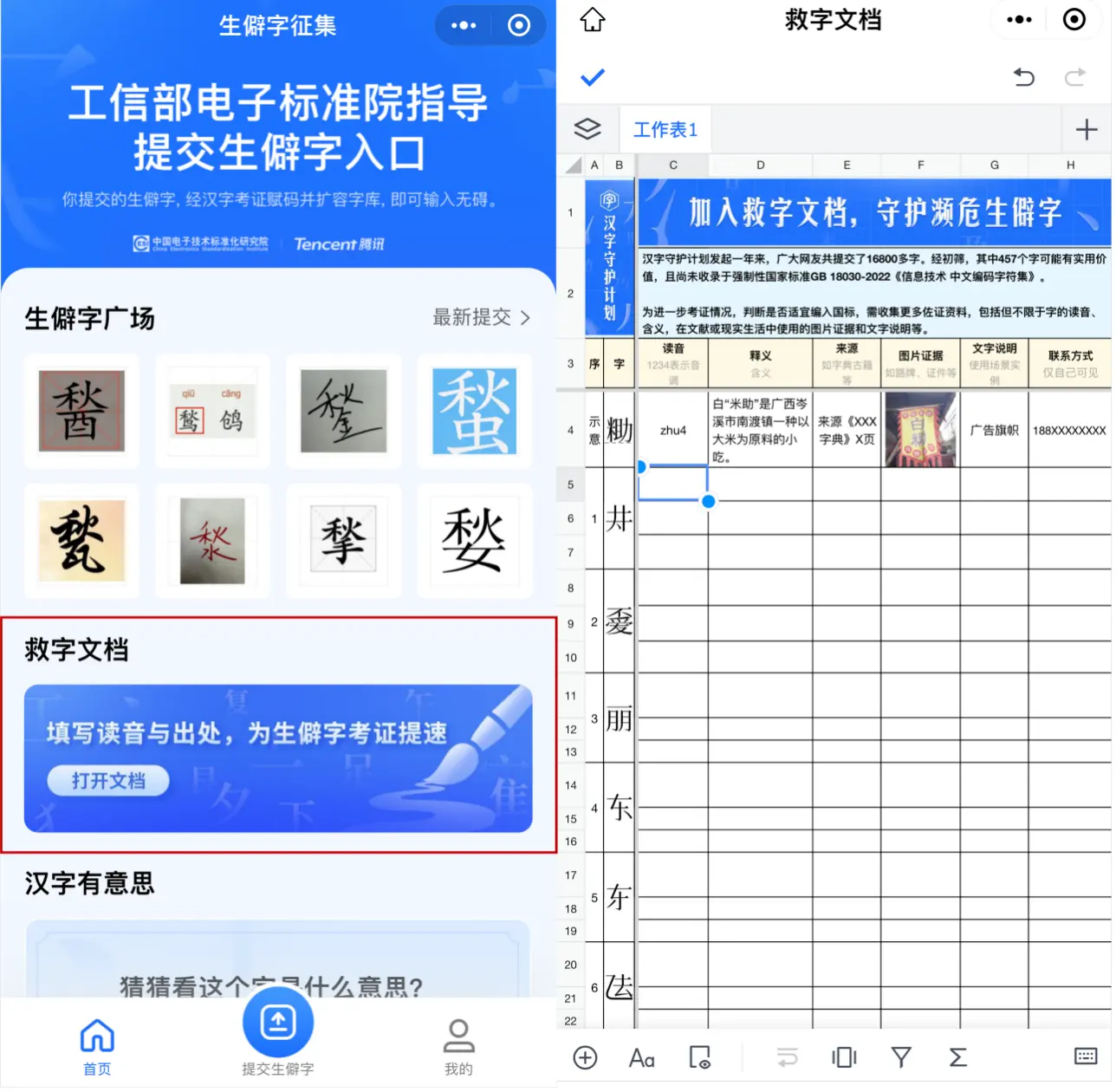
(用“救字文檔”可快速上傳生僻字考證資料)
騰訊輸入法部總經理魯劍表示,“漢字守護計劃關注全鏈路,‘生僻字征集’小程序初見成效,核心在于以民生與文化為出發點,以數字科技匯聚公眾向善之力。此次開發‘救字文檔’,希望發揮平臺的連接作用,讓這些未編碼漢字盡早擁有‘數字身份’。同時,騰訊搜狗輸入法將繼續務實推進生僻字解決方案在金融、醫療等民生場景落地。”
據悉,457個未編碼生僻字中,地名用字328個,占比72%,人名用字66個,占比14%。例如,廣東佛山市高明區的地名用字“土?”(左右結構,專家初步考證音同qǐng),該字用于荷城街道一個鄉村的名字——“下長「土?」村”。當地居民拍下日常生活中該字使用的案例圖片,或發現該字的使用歷史、地方志等文化研究資料,上傳到“救字文檔”,即可助力專家收集考證資料,并實現更高效的針對性考察。
原創文章,作者:蘋果派,如若轉載,請注明出處:http://www.bdzhitong.com/article/594432.html